Late chunking, Contextual,Semantic chunking of PDFs, VLMs and Document AI.

Beyond the Page: A Multi-Modal Journey, Chunking Chaos into Clarity
Introduction
In today’s world of advanced embedding models, we’ve reached a point where long-context, high-token-count inputs can be easily processed for pure text-based content. However, we’re missing out on a wealth of opportunities if we don’t leverage large vision language models to their full potential. These models can revolutionize how we review papers, learn collaboratively, analyze financial documents, and interact with multi-page documents.
Multi-modality is no longer a luxury; it’s become a fundamental aspect of modern AI. In this post, we’ll explore the following key areas:
- Vision Language Models
- The Multi-Modal Journey
- Chunking: Its benefits and challenges in multi-modal contexts
- Transfer learning of Fuyu8B on scientific image, question, and answer datasets
- Recent hacks and future directions
- Research PDF to Vec
Join me as we delve into the exciting world of multi-modal AI and discover how it’s reshaping our interaction with complex, multi-faceted information.
Recap of Vision Language Models
Linear Projection and Linear Transformation
Linear projection is a fundamental concept in linear algebra and machine learning, involving the mapping of data from one space to another while preserving linear relationships. Imagine shining a flashlight on a 3D object to create a 2D shadow on a wall; this shadow is a projection of the 3D object onto a 2D plane. Mathematically, a linear projection is a type of linear transformation, which maps vectors from one vector space to another while preserving vector addition and scalar multiplication. A linear transformation ( T ) from vector space ( V ) to ( W ) can be represented as:
$$ T(av + bu) = aT(v) + bT(u) $$
where ( a ) and ( b ) are scalars, and ( v ) and ( u ) are vectors in ( V ). In matrix form, a linear transformation can be expressed as:
$$ y = Ax $$
where ( A ) is the transformation matrix, ( x ) is the input vector, and ( y ) is the output vector.
Multimodal Projection
Multimodal projection extends the concept of linear projection to multiple modalities, such as text and images. It aims to map data from different modalities into a shared embedding space where they can be compared and processed together. In vision-language models, multimodal projection often involves:
- Projecting image features (from a vision encoder) into a shared space
- Projecting text features (from a language encoder) into the same shared space
This allows the model to perform cross-modal tasks like image-text matching or visual question answering.
Vision Language Models: Key Concepts
Vision Language Models (VLMs) are AI systems designed to understand and process both visual and textual information. They are crucial for tasks requiring joint reasoning over images and text.
Learning Strategies
| Strategy | Description | Pros | Cons |
|---|---|---|---|
| Contrastive Learning | Learns to map similar image-text pairs close together and dissimilar pairs far apart in the embedding space | Effective for learning alignments between modalities | Requires careful negative sampling |
| PrefixLM | Treats image tokens as a prefix for language modeling | Allows for flexible generation tasks | May struggle with fine-grained visual understanding |
| Multi-modal Fusing with Cross Attention | Uses cross-attention mechanisms to fuse information from both modalities | Enables rich interactions between modalities | Computationally expensive |
| MLM / ITM | Masked Language Modeling and Image-Text Matching | Helps learn joint representations | Can be sensitive to masking strategy |
| No Training | Using pretrained vision and language models without joint training | Simple to implement | May miss cross-modal interactions |
+-------------------+ +-------------------+
| Vision Encoder | | Language Encoder |
| (e.g., ViT) | | (e.g., BERT) |
+-------------------+ +-------------------+
| |
v v
+-------------------+ +-------------------+
| Vision Projector | | Language Projector|
+-------------------+ +-------------------+
| |
v v
+-------------------------------------------+
| Shared Embedding Space |
+-------------------------------------------+
|
v
+-------------------------------------------+
| Task-specific Layers/Heads |
+-------------------------------------------+This architecture illustrates the typical components of a vision-language model:
- Separate encoders for vision and language inputs
- Projection layers to map features into a shared space
- A shared embedding space for cross-modal interactions
- Task-specific layers for downstream applications
VLMs have demonstrated remarkable performance on tasks such as visual question answering, image captioning, and visual reasoning. They continue to evolve with larger models, more diverse pretraining datasets, and innovative architectures that push the boundaries of multimodal AI.
Chunking: Its benefits and challenges in multi-modal contexts
Late Chunking and Its Role in Contextual and Semantic Chunking
Basics of Mean Pooling
Mean pooling is a technique used in neural networks to aggregate information by taking the average of a set of values. It is often used to reduce the dimensionality of data or to create a summary representation. An analogy for mean pooling is calculating the average score of a student over multiple exams; instead of focusing on individual scores, you get a single value that represents overall performance. For example, in image processing, mean pooling might be used to reduce the size of feature maps by averaging pixel values in non-overlapping windows across the image. In embeddings, mean pooling helps create fixed-size embeddings from variable-length inputs by averaging the embeddings of all tokens or features, capturing the overall context in a compact form.
Late Chunking
Late chunking is an innovative approach designed to improve the embedding of long-context documents by leveraging long-context embedding models.
The Lost Context Problem
- Traditional chunking methods can lose important contextual information when splitting long texts into smaller chunks.
- This loss occurs because relevant information might be spread across multiple chunks, making it difficult for models to capture dependencies.
The Solution: Late Chunking
- Naive Chunking: Involves splitting text into chunks before applying an embedding model. This can lead to independent and identically distributed (i.i.d.) embeddings, losing context.
- Late Chunking: Applies the transformer layer to the entire text first, generating token-level embeddings. Mean pooling is then applied to these embeddings for each chunk. This method preserves contextual information across chunks, as each chunk embedding is conditioned on the entire text’s context.
| Feature | Naive Chunking | Late Chunking |
|---|---|---|
| Boundary Cues | Used directly in preprocessing | Used after token-level embeddings |
| Resulting Embeddings | i.i.d. | Conditional |
| Contextual Information | Often lost | Well-preserved |
Implementation and Evaluation
- Qualitative Evaluation: Late chunking improves semantic similarity by maintaining context across chunks. For example, references like “the city” and “Berlin” are better linked.
- Quantitative Evaluation on BEIR: Late chunking consistently improved retrieval metrics like nDCG@10 compared to naive chunking.
| Dataset | Avg. Document Length (chars) | Naive Chunking (nDCG@10) | Late Chunking (nDCG@10) |
|---|---|---|---|
| SciFact | 1498.4 | 64.20% | 66.10% |
| TRECCOVID | 1116.7 | 63.36% | 64.70% |
| FiQA2018 | 767.2 | 33.25% | 33.84% |
| NFCorpus | 1589.8 | 23.46% | 29.98% |
Late chunking demonstrates significant improvements, especially for longer documents, by effectively utilizing long-context embedding models like jina-embeddings-v2-base-en. This approach allows for better preservation and conditioning of contextual information within each chunk, enhancing retrieval effectiveness and addressing limitations of traditional i.i.d. chunk embeddings.
Challenges of Late Chunking for PDFs and Nuances, Next Steps
In our journey to enhance document understanding and retrieval, we’ve developed a sophisticated approach to process PDF documents using late chunking and context-aware embeddings. This method aims to preserve the rich structure and visual context of PDFs while creating meaningful representations for efficient retrieval. Let’s dive into the challenges we faced and the solutions we implemented.
Structuring Technical Paper-based PDFs
Our first challenge was to create a structured representation of PDF documents that captures both textual and visual elements. We designed a hierarchical data model using custom classes:
class PDFSegment(BaseDoc):
page_number: int
segment_type: str # 'text', 'image', 'table', or 'hybrid'
content: Optional[str]
image: Optional[ImageTensor]
position: Dict[str, int] # {x, y, width, height}
relationships: Dict[str, Optional[str]] # {'prev': id, 'next': id, 'parent': id}
embedding: Optional[NdArray[768]]
class PDFPage(BaseDoc):
page_number: int
screenshot: ImageTensor
embedding: Optional[NdArray[768]] = None
class RichPDFDocument(BaseDoc):
file_path: str
num_pages: int
segments: DocList[PDFSegment]
pages: DocList[PDFPage]This structure allows us to represent individual segments (text, images, tables) within pages, as well as full-page screenshots. The relationships field in PDFSegment is crucial for maintaining the document’s structure and context.
Leveraging JINA CLIP API for Late Chunking
To create embeddings for our structured PDF representation, we utilized the JINA CLIP API. This powerful tool allows us to generate embeddings for both textual and visual content. Here’s how we processed our PDF segments and pages:
def create_embeddings_for_rich_pdf(rich_pdf: RichPDFDocument, api_token: str) -> RichPDFDocument:
input_data = []
# Process segments and pages...
api_response = call_jina_clip_api(api_token, input_data)
# Assign embeddings to segments and pages...
return rich_pdfThis function prepares the input data for the API call, processes both textual and image segments, and even includes full-page screenshots. The resulting embeddings are then assigned to their respective segments and pages.
Applying Contextual and Late Chunking
The heart of our approach lies in creating context-aware embeddings and applying late chunking. This process involves two key steps:
1) Context-Aware Embeddings: We enhance each segment’s embedding by considering its relationships with neighboring segments:
def create_context_aware_embeddings(
embeddings: List[np.ndarray],
relationships: List[Dict[str, Optional[str]]],
rich_pdf: RichPDFDocument,
alpha: float = 0.2) -> List[np.ndarray]:
# Create context-aware embeddings...This function blends each segment’s embedding with those of its related segments, creating a more contextually rich representation.
2) Late Chunking: We then apply late chunking to these context-aware embeddings:
def create_late_chunks(
embeddings: List[np.ndarray],
metadata: List[Dict],
chunk_size: int = 5,
stride: int = 2) -> Tuple[List[np.ndarray], List[Dict]]:
# Create late chunks...This process creates overlapping chunks of embeddings, allowing for a more flexible and context-preserving representation of the document.
3) Creating a Collection of Conditioned Embeddings
The final step in our pipeline is to create a collection of embeddings that are conditioned on each other, bidirectional, and preserve visual and longer context. We achieve this through our late_chunking_pipeline function:
def late_chunking_pipeline(rich_pdf: RichPDFDocument) -> Tuple[List[np.ndarray], List[Dict]]:
# Process segments and pages
# Create context-aware embeddings
# Create late chunks
return late_chunks, late_chunks_metadataThis pipeline ensures that our final embeddings capture the essence of the document’s structure, content, and visual elements. Storing Context for Each Chunk
To make our embeddings searchable and retrievable, we store them in a Pinecone index:
def create_pinecone_index(
rich_late_embeddings: List[np.ndarray],
rich_late_metadata: List[Dict],
index_name: str):
# Create and populate Pinecone index...This function not only stores the embeddings but also preserves crucial metadata about each chunk, including the segment types, page numbers, and simplified content.
Challenges and Next Steps
While our approach offers a sophisticated method for processing PDFs, we faced several challenges:
- Balancing Granularity and Efficiency: Determining the optimal chunk size and stride for late chunking is crucial. Too small, and we lose context; too large, and we sacrifice granularity.
- Handling Large Documents: Processing very large PDFs can be computationally expensive. We need to explore optimization techniques for scaling our approach.
- Preserving Visual Context: While we include full-page screenshots, fully capturing the visual layout and its relationship to the text remains a challenge.
- Query Processing: Our next step is to develop an efficient method for processing queries against our rich, context-aware embeddings.
- Evaluation Metrics: Developing comprehensive metrics to evaluate the effectiveness of our approach in real-world retrieval scenarios is crucial.
As we move forward, we aim to refine our late chunking approach, explore more advanced visual-textual models, and develop sophisticated querying mechanisms that can fully leverage the rich, context-aware embeddings we’ve created.
Fuyu-8B, SPIQA, and Transfer Learning for Visual Question Answering on Research PDFs
Fuyu-8B: A Unique Vision-Language Model
Fuyu-8B is an innovative vision-language model developed by Adept AI. Unlike traditional models that use separate encoders for images and text, Fuyu-8B employs a unified architecture:
- No Dedicated Image Encoder: Fuyu-8B processes images directly within its transformer layers, eliminating the need for a separate image encoder.
- Flexible Input Handling: It can handle variable-sized images and multiple images per prompt without requiring fixed-size inputs or image patching.
- Efficient Architecture: With only 8 billion parameters, Fuyu-8B achieves competitive performance while being more computationally efficient than larger models.
SPIQA Dataset: Advancing Visual Question Answering
The Semantic Parsing for Image Question Answering (SPIQA) dataset, introduced by Google, aims to improve visual question answering (VQA) capabilities:
- Complex Reasoning: SPIQA focuses on questions requiring multi-step reasoning and understanding of spatial relationships.
- Structured Outputs: Unlike traditional VQA datasets, SPIQA requires models to generate structured outputs (programs) that can be executed to answer questions.
- Evaluation Metrics: SPIQA introduces new metrics to assess both the correctness of generated programs and final answers.
Transfer Learning vs. Fine-Tuning
Understanding the difference between transfer learning and fine-tuning is crucial for adapting models to new tasks:
- Transfer Learning: This broader concept involves using knowledge gained from one task to improve performance on a different but related task. It often includes freezing pre-trained layers and adding new task-specific layers.
- Fine-Tuning: A specific form of transfer learning where a pre-trained model is further trained on a new dataset, usually with a lower learning rate. All or most layers of the model are updated during this process.
Pitfalls of Fine-Tuning
Fine-tuning can sometimes lead to:
- Catastrophic Forgetting: The model may lose its ability to perform well on the original task it was trained for.
- Overfitting: Especially when fine-tuning on small datasets, the model may become too specialized and lose generalization ability.
How Transfer Learning Helps
Transfer learning can mitigate these issues by:
- Preserving General Knowledge: By freezing certain layers, the model retains its pre-trained knowledge.
- Efficient Adaptation: It allows for quicker adaptation to new tasks with less data.
- Improved Generalization: The model can leverage its broad knowledge base while learning task-specific features.
Adapting Fuyu-8B for Research PDF Visual QA
The provided code demonstrates how to adapt Fuyu-8B for visual question answering on research PDFs using transfer learning techniques. Here are key aspects of the implementation:
Adapting Fuyu-8B for Research PDF Visual QA
The provided code demonstrates how to adapt Fuyu-8B for visual question answering on research PDFs using transfer learning techniques. Here are key aspects of the implementation:
class FuyuDataset(Dataset):
def __init__(self, data, image_dir, processor):
# ... (initialization code)
def __getitem__(self, idx):
# ... (load and process image)
return {
"text": item['question'],
"image": processed_image,
"answer": item['answer'],
"original_image": original_image
}
This custom dataset class prepares the data for Fuyu-8B, including image processing.
Selective Layer Unfreezing:
# Freeze all parameters first
for param in model.parameters():
param.requires_grad = False
# Unfreeze specific layers
for name, param in model.named_parameters():
if any(layer_name in name for layer_name in [
"lm_head",
"final_layernorm",
"layers.35", # Last layer of the transformer
"vision_embed_tokens"
]):
param.requires_grad = TrueThis code demonstrates a transfer learning approach by freezing most of the model’s parameters and only fine-tuning specific layers.
This implementation showcases how to effectively adapt a powerful vision-language model like Fuyu-8B to a specific task (visual QA on research PDFs) using transfer learning techniques. By selectively unfreezing layers and using a custom dataset, the code aims to leverage Fuyu-8B’s pre-trained knowledge while adapting it to the nuances of research PDF analysis.
Here is the dataset and model from my Huggingface profile.
- SpiQA simplified
- [Full Precision Fuyu8B Transfer Learned on above dataset] (https://huggingface.co/sugiv/Fuyu-8b-transfer-learned-spiqa-simplified)
Multi Modality, Multi Page PDFs, Research PDFs, Financial Documents
When dealing with pure text, creating various kinds of chunks with metadata is relatively straightforward. As discussed in the late chunking section, late chunking techniques allow us to create bi-directional, interdependent, mean-pooled collections of embeddings that support longer contexts. These embeddings are derived from the late chunking process.
However, consider multi-page PDFs, such as well-known research papers. From the abstract to the conclusion, these documents contain text, images like architectural diagrams and flowcharts, code blocks, tables, data visualizations, and image captions (text), all intricately connected. Contextual chunking in this context is both challenging and essential. The relative positioning and hierarchical relationships within the document are crucial. Late chunking becomes exceedingly difficult and nearly impossible for multi-page PDFs, especially those spanning hundreds or thousands of pages, without segmenting the document.
Given these unique challenges, it is vital to process PDFs effectively to enable multi-modal retrieval.
Before delving further into this topic, let’s review a research paper and discuss my strategies for creating late contextual chunks for research publications. I will also share my findings related to financial documents, using a recent United States financial report as an example.
Understanding Contrastive Learning and Contrastive Loss
Contrastive Learning
Contrastive learning is a machine learning method where the model learns to differentiate between similar and dissimilar pairs of data points. The objective is to map similar pairs closer together in the feature space while pushing dissimilar pairs further apart. An analogy for contrastive learning is organizing a photo album: photos from the same event (similar) are placed together, while photos from different events (dissimilar) are placed in separate sections. For example, in a dataset of animal images, a model might learn to cluster images of cats closely in the embedding space while distancing them from images of dogs.
Contrastive Loss
Importance: Contrastive loss is the objective function used in contrastive learning. It measures how well the model distinguishes between similar and dissimilar pairs.
Relation to Contrastive Learning: The loss function guides the model during training by penalizing it when similar pairs are far apart or dissimilar pairs are too close.
InfoNCE Loss and Derivation
InfoNCE Loss Formula:
L(Q, D+, DN) = -log(exp(Sim(Q, D+)/τ) / ΣDi∈{D+}∪DN exp(Sim(Q, Di)/τ)) Components: D+: Positive document. DN: Set of negative documents. τ: Temperature parameter controlling distribution sharpness. Sim(Q, D): Cosine similarity between query Q and document D embeddings.Gradient Descent Role: Gradient descent minimizes this loss. During backpropagation, gradients of the loss with respect to model parameters are computed, allowing the model to update its weights and improve its ability to distinguish between similar and dissimilar pairs.
Derivation of Gradients for InfoNCE Loss
- Partial Derivative with Respect to Positive Pair:
∂L/∂Vq = (1/τ) * p(D = Di | Q) * Vdi
∂L/∂Vq = -(1/τ) * (1 - p(D = D+ | Q)) * Vd+ Here,
p(D = D+ | Q) is the probability assigned to the positive pair being correct.- Partial Derivative with Respect to Negative Pairs:
For each negative document ( D_i ):
∂L/∂Vq = (1/τ) * p(D = Di | Q) * VdiThese gradients allow for adjusting embeddings during training, ensuring that positive pairs are brought closer while negative pairs are pushed apart.
Mathematical Formula in Contrastive Learning Section
- Cosine Similarity Calculation:
The similarity between query Q and document D is calculated using cosine similarity:
Sim(Q, D) = (Vq · Vd) / (||Vq|| * ||Vd||)
Here, Vq and Vd represent embeddings for query and document respectively.InfoNCE Loss Usage:
The model optimizes embeddings using InfoNCE loss for retrieval tasks. This aligns document and query embeddings by bringing relevant documents closer in the embedding space to their corresponding queries.
Authors Approach Using Contrastive Learning
Embedding Calculation:
- Document embeddings (( V_d )) are obtained from a vision-language model using document screenshots.
- Query embeddings (( V_q )) are derived from text inputs using a language model.
Training Strategy:
- The model employs contrastive learning with InfoNCE loss to align document and query embeddings effectively.
- This alignment enhances retrieval accuracy by ensuring that relevant documents are closer in the embedding space to their corresponding queries.
By employing contrastive learning with InfoNCE loss, models can effectively capture meaningful relationships within data, improving performance on tasks like information retrieval.
Dual Approach
Task Definition
The paper defines the document retrieval task as follows:
- Objective: The goal is to identify the ( k ) most relevant documents from a corpus ( C ) for a given query ( Q ), where ( k ) is much smaller than the total number of documents ( n ).
- Relevance Metric: Relevance between the query and each document is measured using a similarity metric Sim(Q, D).
- Document Format: In this work, a “document” refers to a complete information snippet, such as a web article or PDF page, captured as a screenshot. This differs from previous work where “documents” could be smaller snippets like sentences or passages.
- Query Format: Only text inputs are considered for queries, similar to traditional search settings. Handling image queries is left for future exploration.
Why Vision-Language Models Over CLIP
The authors chose large vision-language models over CLIP’s vision encoder because:
- Fine-Grained Information: CLIP’s vision encoder struggled to capture fine-grained details in screenshots, especially when text is dense (e.g., Wikipedia pages).
- Enhanced Capability: Vision-language models like Phi-3-vision can handle more detailed image analysis by representing images with more patches, allowing for better textual information capture.
Document Screenshot Embedding
The authors propose a method using a bi-encoder architecture for dense retrieval:
Bi-Encoder Architecture:
- Vision Encoder: Encodes document screenshots into dense vectors.
- Text Encoder: Encodes user text queries into dense vectors.
Vision Encoder Process:
- Screenshots are divided into patches (e.g., 24x24) and processed by the vision encoder.
- Each patch is flattened and mapped to a latent representation using linear projection.
- CLIP’s approach was limited to 576 patches, which was insufficient for detailed text information.
Vision Language Model Enhancement:
- Uses the Phi-3-vision model to represent images with more patches by dividing them into sub-images.
- This method captures both local and global information by encoding additional patches for the entire screenshot.
Encoding Process:
- The screenshot is divided into sub-images, each encoded independently.
- Additional global encoding captures overall screenshot context.
- Patch embeddings are concatenated with a text prompt for input to the language model.
Uni-Directional Attention and Special Tokens:
- The model uses uni-directional attention to aggregate information effectively.
- A special
<img>token represents the sequence of patch embeddings. - The end-of-sequence token
</s>is used from the last hidden state as the final document screenshot embedding, ensuring comprehensive aggregation of information.
Nuances of Patch Limitations in CLIP
Patch Limitation in CLIP:
- CLIP’s vision encoder divides an image into a fixed number of patches (e.g., 24x24, totaling 576 patches).
- This approach limits the ability to capture fine-grained details, especially in text-heavy images like Wikipedia pages, where detailed textual information is crucial.
How Vision-Language Models Circumvent Limitations
Vision-Language Model Approach:
- The Phi-3-vision model enhances detail capture by dividing images into more patches through sub-image cropping.
- Screenshots are resized to larger dimensions and divided into sub-images, each further divided into patches.
Screenshot Division Process
Initial Division:
- Convert a screenshot into an image with dimensions ( (C_x \times 336) \times (C_y \times 336) ).
- Divide this image into ( C_x \times C_y ) sub-images, each of size ( 336 \times 336 ).
Patch Representation:
- Each sub-image is divided into 576 patches (24x24).
- An additional global representation is created by converting the entire screenshot into 576 patches.
Total Patch Embeddings:
- Total latent representations: ( (C_x \times C_y + 1) \times 576 ).
- For input to the language model, every four patch embeddings are merged: ( (C_x \times C_y + 1) \times \frac5764 ).
Authors then discuss global and local features:
Global features: These are derived from the entire image resized to 336 × 336 pixels. Analogy: It’s like looking at a zoomed-out version of a map to understand the overall layout. Local features: These come from a higher-resolution image (1344 × 1344 pixels) divided into 16 (4x4) sub-images. Analogy: It’s like zooming in on specific neighborhoods in the map to see street-level details.
The authors observed that:
Global attention heads focus on general information (images, logos, titles, sections). This is like identifying major landmarks or regions in a city. Local attention heads concentrate on finer details (individual letters, keywords). This is akin to reading street names or building numbers.
This dual approach allows the model to capture both broad context and specific details, which is crucial for effective document retrieval.
My Approach
Compared to financial documents, which will be discussed in a different section below, research papers are relatively easier to handle. My approach involves segmenting PDFs into images and text. Images can include tables, architectural diagrams, data visualizations, code blocks, and text. Additionally, a screenshot of each page is captured at the page level to provide visual context, which is used in low resolution when prompting the vision-language model. I am pleased with the multi-modal retrieval results for research PDFs.
Unlike the Dense Screenshot Embedding paper, my approach differs slightly while still employing a dual strategy. Individual page screenshots offer visual context and serve as additional references, whereas individual segments provide local references. I create embeddings for the entire page and individual segments while maintaining the hierarchical structure of the page. Refer to the custom data class mentioned above for each multi-page PDF.
After generating embeddings, I perform contextual chunking as previously explained. Although it is not a direct counterpart of text-based late chunking, I still produce conditioned, bi-directional, contextual chunks of the entire multi-page research papers. This process involves some complexity but is necessary for handling multi-page PDFs and research papers.
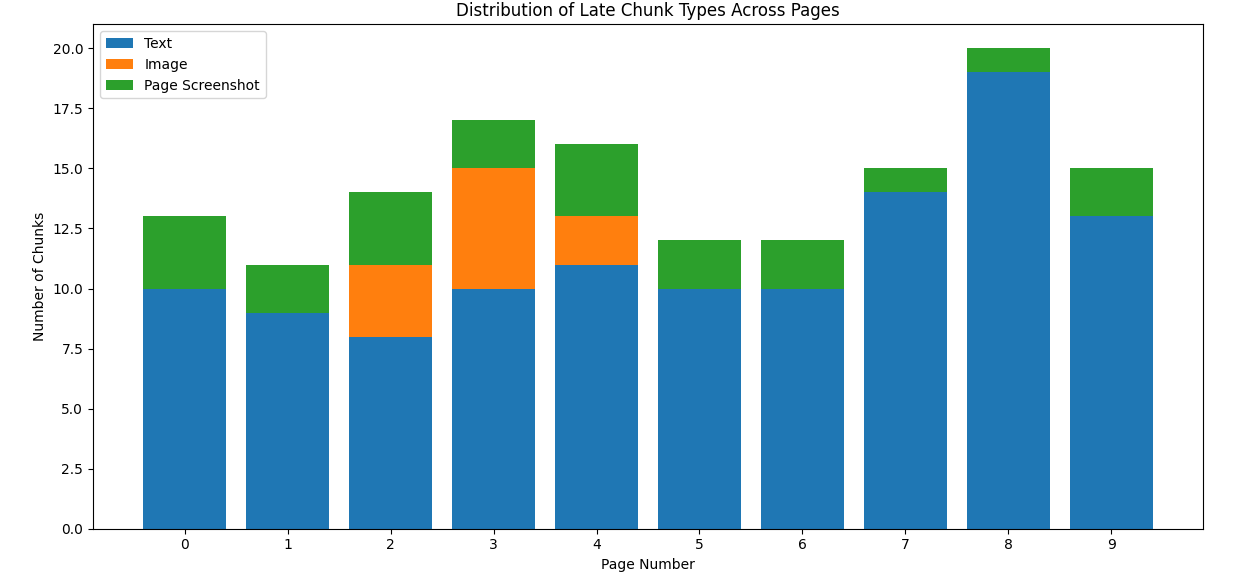
Chunks of Attention is all you need paper, each chunk has text segment, image segment and page screenshot
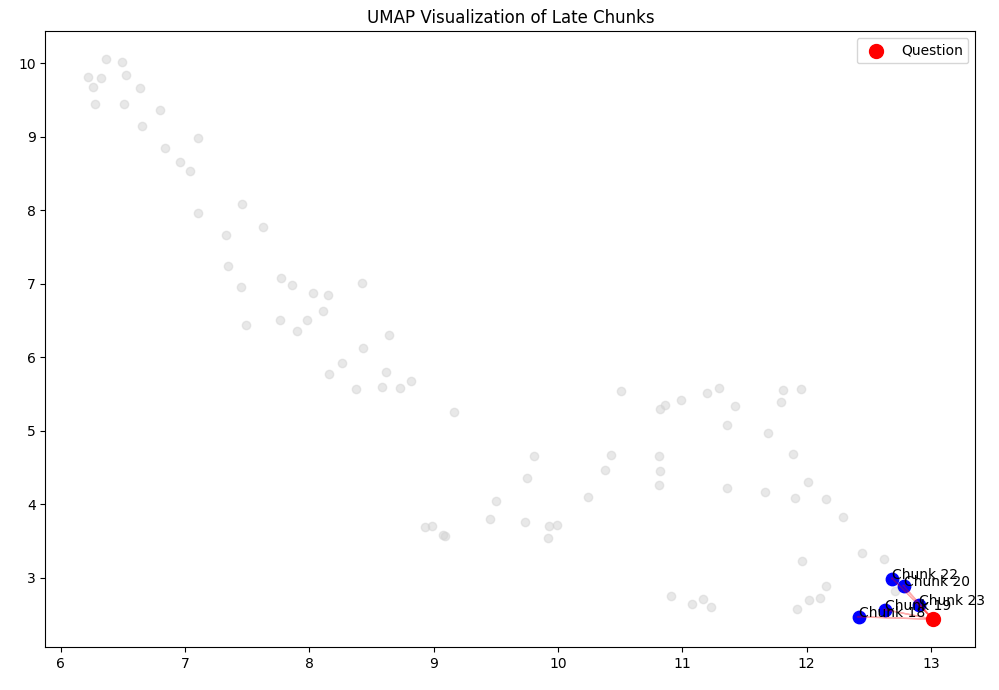
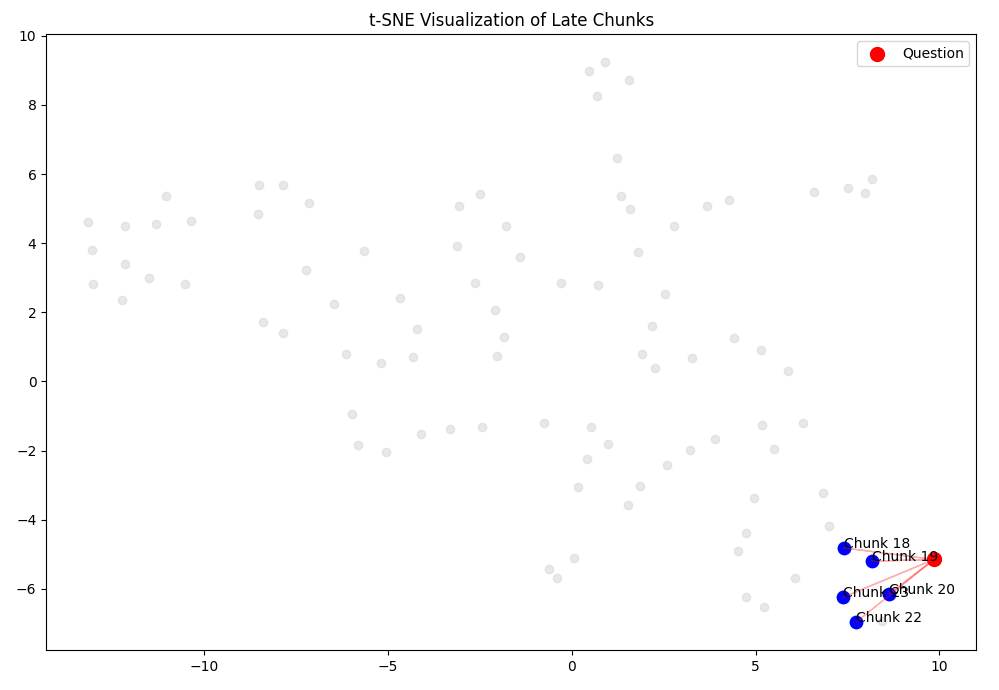
For a question asked, how retrieval finds the relevant chunks
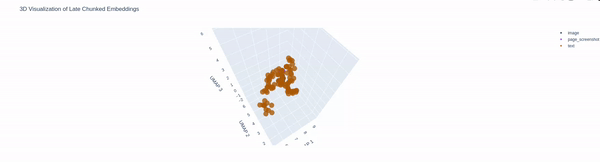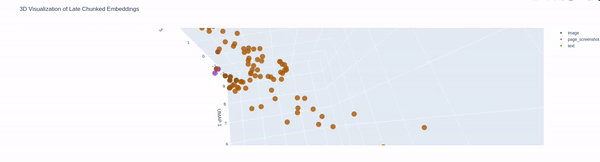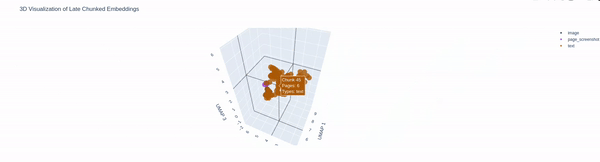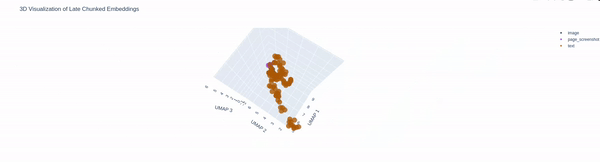
Demo
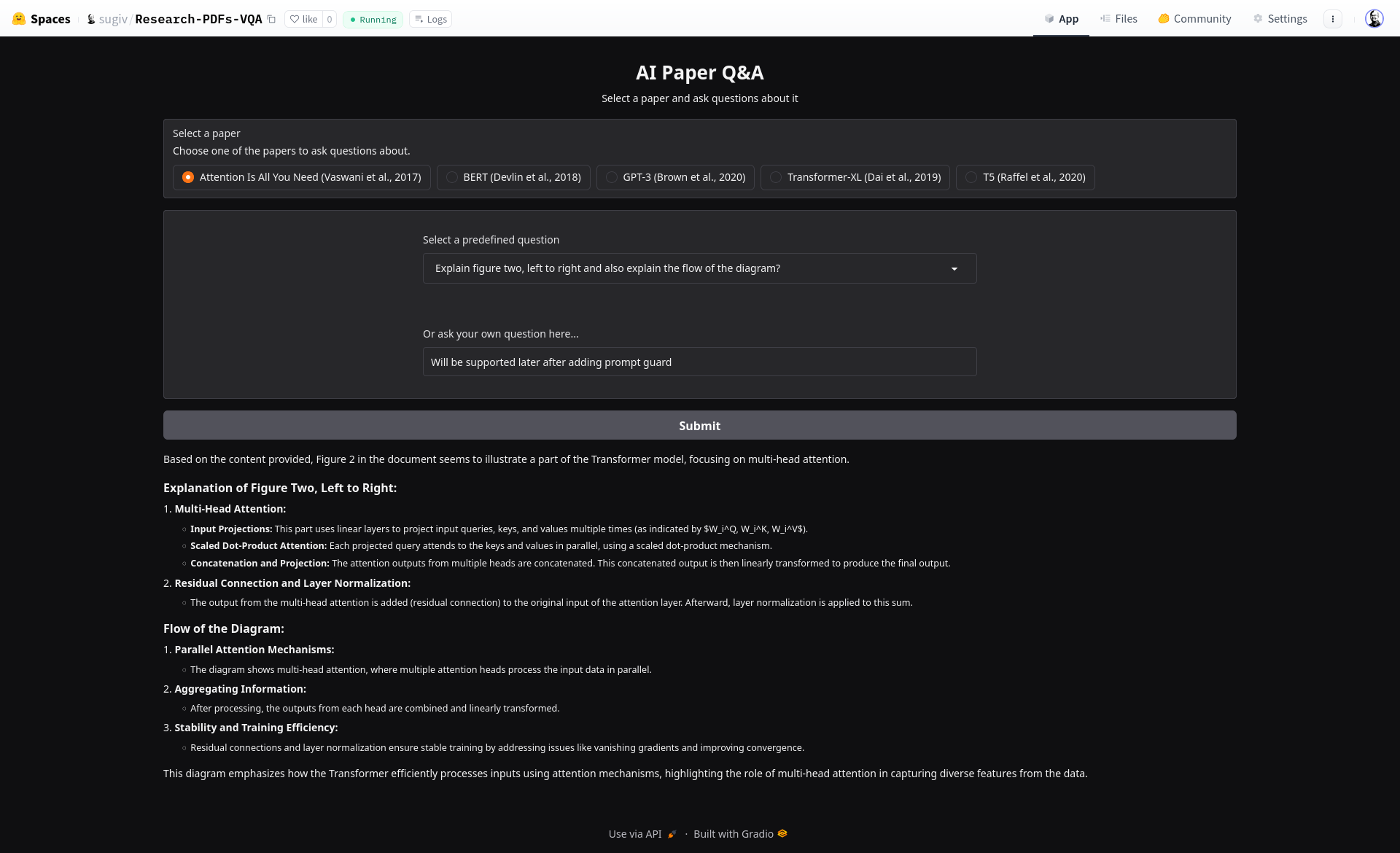
- I am GPU poor and resource poor. I have only processed one famous paper, but, I can add more papers easily and enable ask your own question after I add prompt garuds. For now, you can ask pre generated and pre answered neural visual questions on “Attention is all you need” paper. Feel free to explore the Huggingface space. It is using my free Huggingface account, so the space can sleep eventually.
Financial Multi Page Documents (Nuances)
Please refer to #Patch Limitation in CLIP above and for research PDFs, JINA CLIP was sufficient but not for financial documents.
How is financial documents different than research PDFs?
Let us take current fiscal year United States financial report available for free at here.
Take a look at large, almost full page
- Tables (of numericals and calculations but not necessarily well structure tables).
- Large Data visualization charts like bar chart, pie charts, histograms.
- As usual, text with Financial jargons.
That said, the approach which worked well for chunk retrieval for research PDF’s didn’t work well for financial documents even after creating both dense and sparse embeddings. Its time to use vision language model in the same way, Dense screen shot embedding, authors have used but follow slightlt aggressive technique to process, create contextual chunks.
I am pasting one of the best retrieval efforts I encountered but like I said, there is room for improvement when it comes to financial documents.
Question - Referring to Table 5 in the report, what was the total amount of federal debt held by the public at the end of fiscal year 2023, and how much did it increase compared to the previous fiscal year?
Answer generated by model based on few shot prompt created with multi modal retrieval - Answer: Referring to Table 5 and the relevant excerpts from the report, the total amount of federal debt held by the public at the end of fiscal year 2023 was $26.3 trillion. This represents an increase of $2.0 trillion compared to the previous fiscal year.
This information is supported by Excerpt 1 on Page 12, which states: “During FY 2023, federal debt held by the public increased $2.0 trillion (8.3 percent) to $26.3 trillion.”

Many pages, lot of chunks and here are some visualization for the above said financial document
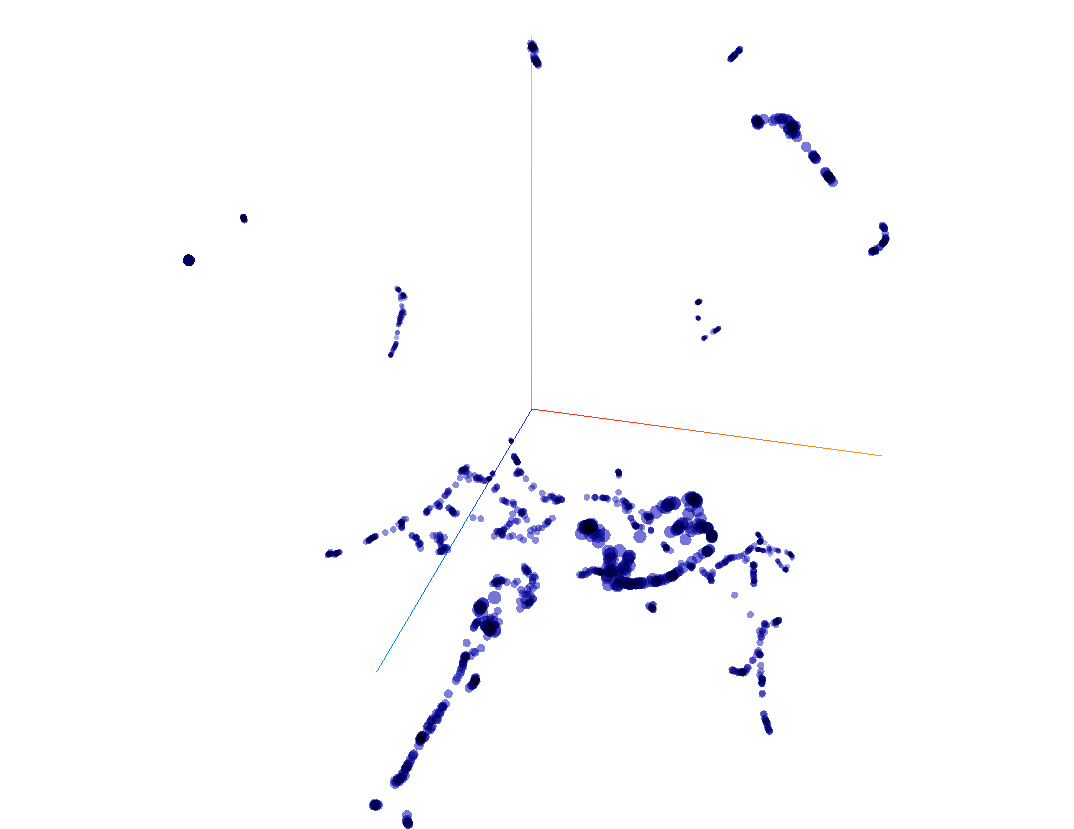
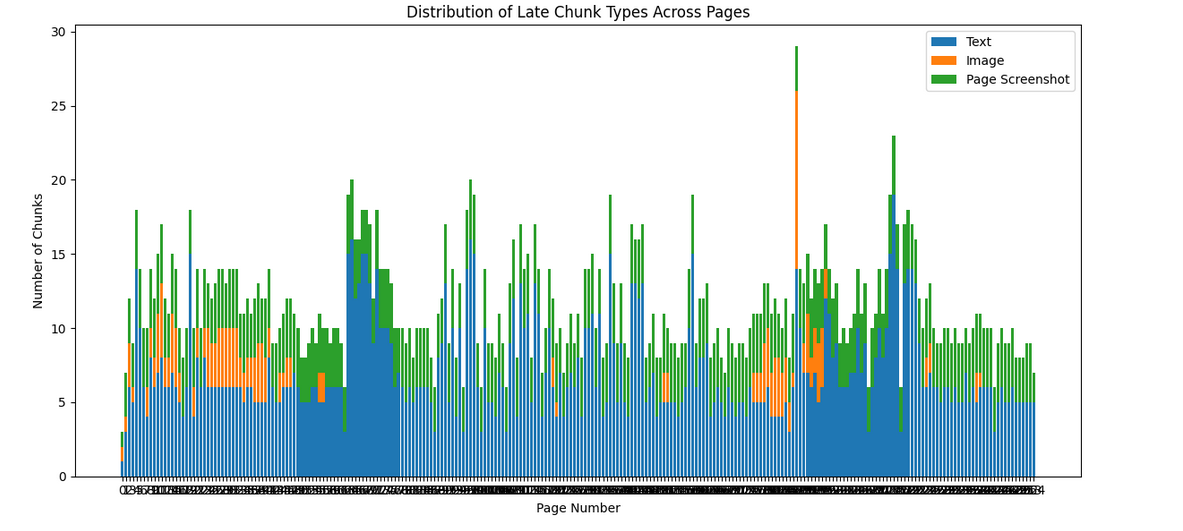
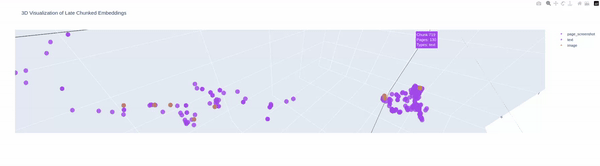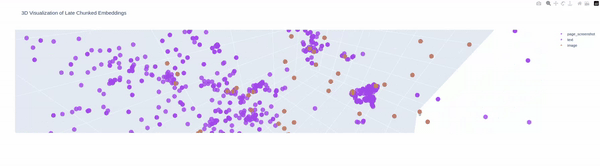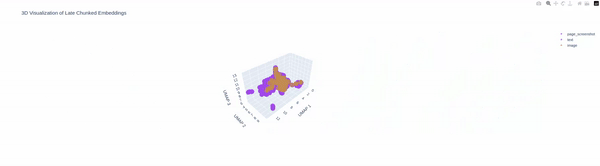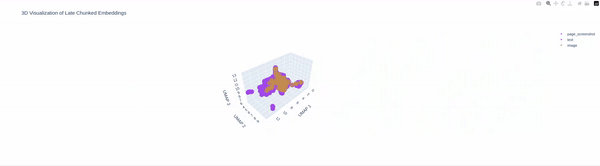

Next Steps
- Improve accuracy of Financial multi page documents based retrieval accuracy.
- Build in house visual language model fine tuned to answer visual questions on Financial documents.
- Index more research papers from my PDF shelf.
References
- [Late Chunking JINA AI] (https://jina.ai/news/late-chunking-in-long-context-embedding-models/)
- [Hugging Face] (https://huggingface.co/blog/vlms)
- JINA-CLIP
- Late Chunking Paper
- Adept